NTFS Transaction Journal
NTFS log provides file system recoverability by logging, or recording, the operations required for any transaction that alters important file system data structures. This is done before these operations are carried through on the disk. This process ensures that if the system crashes, partially completed transactions can be redone or undone when the system comes back online.
The NTFS considers every modification to a file system through an I/O operation as a transaction, modified on a file in an NTFS volume.
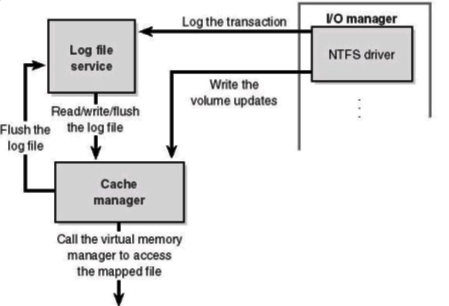
The LFS, or the log file service, was designed to provide logging and recovery services for the NTFS. The LFS consists of a series of kernel-mode routines inside the NTFS driver, used to access the log file. The log file is divided into two regions, the restart area and the "infinite" logging area.

NTFS calls the LFS to read and write the restart area, using it to store context information, such as the location in the logging area from which the NTFS will begin reading from during a recovery from a system failure.
The LFS also stores a second copy of the restart data in case the first becomes somehow corrupted or inaccessible, guaranteeing that at least one area will work. The rest of the log file consists of a logging area that works in a circular fashion, making it "infinite", as mentioned before. New records are added to the end of the file until the Log File reaches its full capacity, then the LFS waits for the writes to occur and space is freed up for new records.
The services that the LFS provides for the NTFS consist of: opening the log file, writing the log records, reading log records in both forward and backward order, flushing the records up to a particular LSN(Log Sequence Number) and setting the beginning of the log file to a higher LSN. The NTFS itself calls the LFS to record any transactions that modify the volume structure, storing it in the cached log file.
The cache then prompts the LFS to flush the log file to the disk. The LFS would then implement that command by calling the cache manager back, finding which pages of memory to flush. After the log file is flushed to the disk, the volume change operations themselves (metadata operations) are flushed to the disk.
Log Update Records
The LFS allows the NTFS to write any kind of record to the log files, including update records and checkpoint records. Update records contain two kinds of information: redo information and undo information.
Redo information tells how to reapply one sub-operation of a fully logged transaction to the volume if a system error were to occur before the transaction was flushed from the cache. Undo information tells how to reverse a sub-operation of a transaction that was only partially logged at the time of the potential system failure.
Each record represents a sub-operation of a transaction. The redo entry in the update record tells the NTFS how to reapply the sub-operation and the undo entry tells NTFS how to roll back the sub-operation.

Logging
After a transaction is logged, the NTFS performs the sub-operations on the volume itself, in the cache. Finally, after the cache has been updated, NTFS writes another record to the log file, recording that the transaction has been completed.
When a system is being recovered after a system failure, the NTFS reads through the log file and redoes each committed transaction. After that, the NTFS locates all of the transactions in the log file that weren't committed at the failure and rolls back.
By the format of the update records, executing redundant redo and undo operations does not change the end result.
NTFS writes update records for creating a file, deleting a file, extending a file, truncating a file, setting file information, renaming a file and changing the security applied to a file. As well as update records, NTFS also writes a checkpoint record to a log file.

These checkpoint records are made to tell NTFS what processing would be needed to recover a volume if a crash were to occur immediately. After this checkpoint record is made, the LSN of the record is stored by the NTFS in the restart area.
Log Full
If a log file does not contain enough available space, the log file service (LFS) returns a "log file full" error and the NTFS raises an exception. The NTFS exception handler rolls back the current transaction and places it in a queue to be restarted later.
The NTFS then blocks file creation and deletion and then requests exclusive access to all system files and shared access to all user files. Gradually, active transactions are either completed successfully or they receive the "log file full" exception. All the transactions that receive the exception are rolled back.
After flushing to disk, the NTFS resets the beginning of the log file to the current position, making the log file "empty". Then it restarts the queued transactions.
NTFS Transaction rollback
The NTFS recovery pass is conducted in 6 steps:
-
The MFT is read once an NTFS volume is recognized.
-
The LFS is called on by the NTFS to open the log file, causing the Log File Service Recovery to occur.
-
The LFS is called on by the NTFS to read the restart data and the data is read from the last checkpoint operation. This data is used to initialize the transaction table, dirty pages table and open file table to be used in the recovery process.
-
An analysis pass is performed by the NTFS on its last checkpoint record. Upon completion of this, the transaction table only contains the transactions that were active when the crash occurred.
-
A redo pass is performed by the NTFS, so that the cache reflects the state of the volume where the crash occurred.
-
NTFS performs an undo pass, recovering the volume to a stable state.
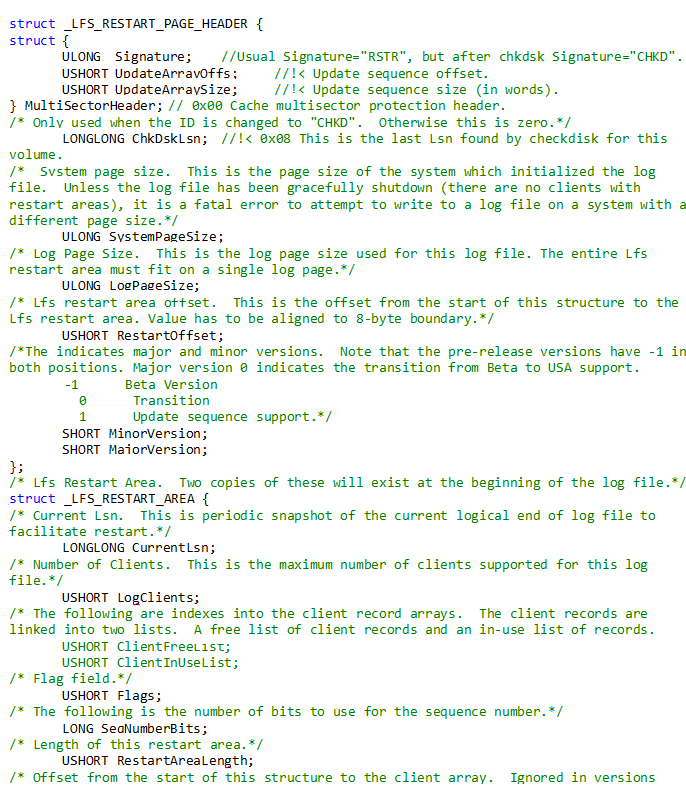
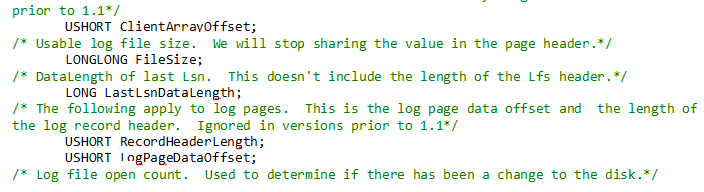
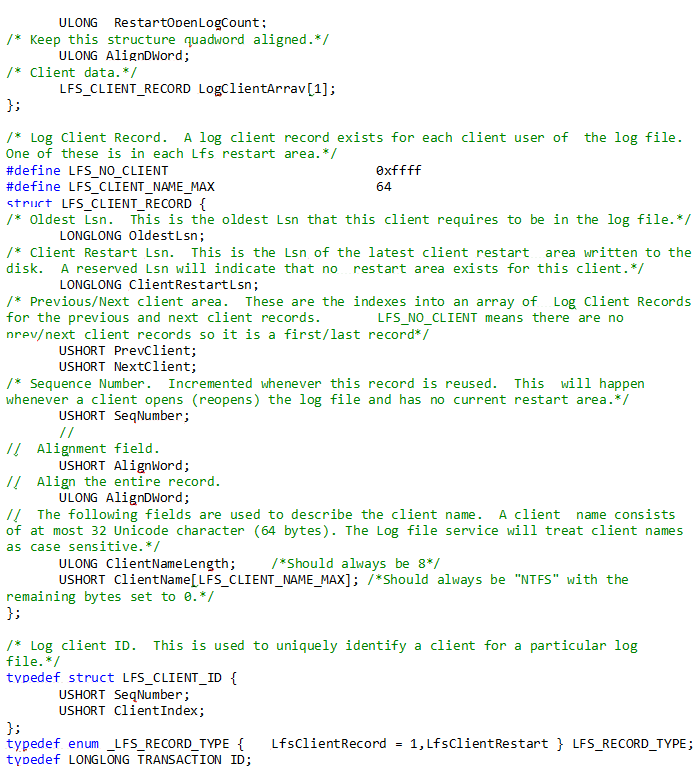
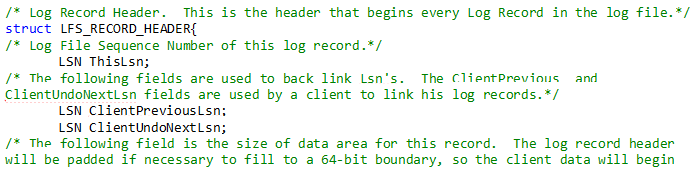
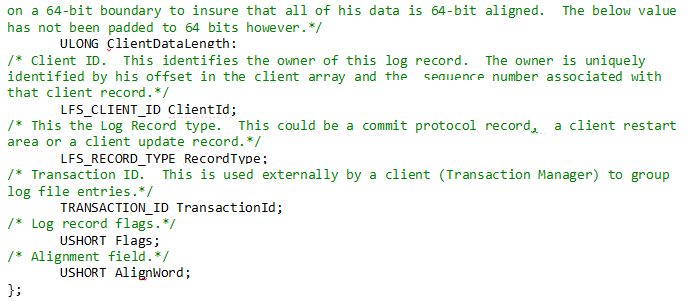
C++ explanation: C++ explains this $LogFile on disk structures in the following way:
The Log File Service is used on systems that require that on-disk structures guarantee the natural alignment of all arithmetic quantities up to and including quad-word (64-bit) numbers. Therefore, all LFS on-disk structures are quad-word aligned.